
JJUNNAK's
[ R ] 데이터셋 Dataset, 데이터 조작 함수 모음 본문
데이터셋
Dataset
데이터셋이란?
분석을 위하여 2차원의 형태로 모아놓은 자료를 말한다.
R에서는 기본적으로 제공해주는 데이터셋들이 있으며
각 패키지에서 제공해주는 데이터셋들도 있다.
데이터셋 정보 확인
[ Iris(붓꽃) 데이터셋 ]
iris 데이터셋은 R에 기본적으로 내장되어있는 데이터셋으로
붓꽃의 3가지 종(setosa, versicolor, virginica)에 대해
꽃받침sepal과 꽃잎petal의 길이를 정리한 데이터이다.
- 데이터셋 불러오기.
iris # iris 데이터셋 불러옴
> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
.
.
.
.
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
2. 데이터셋 정보확인 함수
class(iris) # 데이터셋 자료구조 확인
> "data.frame"
dim(iris) # 행과 열의 개수 표시
> 150 5
nrow(iris) # 행의 개수 표시
> 150
ncol(iris) # 열의 개수 표시
> 5
colnames(iris) # 열 이름 표시 == names() 함수와 결과 동일
> "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
head(iris) # 데이터셋 앞부분 일부 표시
tail(iris) # 데이터셋 뒷부분 일부 표시str(iris) # 데이터셋 요약정보 표시
> 'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
levels(iris[,5]) # 품종의 종류 표시 (중복제거)
> "setosa" "versicolor" "virginica"
table(iris[,"Species"]) # 품종의 종류별 행 개수 표시
> setosa versicolor virginica
50 50 50위의 str() 함수는 데이터셋의 전반적인 정보를 알아낼 수 있는 함수이다.
실행 결과에서 'data.frame': 150 obs. of 5 variables: 는
데이터프레임 자료구조에 150개의 관측값(observations) , 5개의 변수(열)에 존재하고 있음을 나타낸다.
levels() 함수는 어떤 그룹을 나타내는 팩터 자료에 중복값을 제거하고 값의종류를 바로 알 수 있는 함수이다
table() 함수는 각 그룹별로 몇개의 관측값(행) 이 존재하는지 알려주는 함수이다.
그룹별로 몇개의 값이 있는지 정리한 것을 "도수 분포표" 라고 한다.
데이터 연산,조작 함수
R에서는 저장된 데이터를 자유자재로 다룰 수 있는 다양한 함수를 제공한다.
아래 예시는 계속해서 iris 데이터셋을 사용한다.
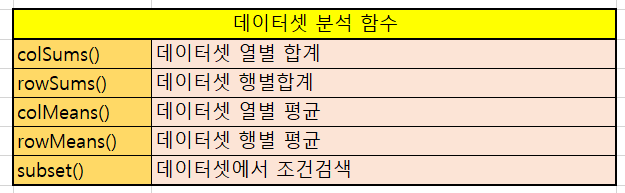
- 행,열별 합계,평균 계산
* iris 5열의 품종 데이터는 팩터 형태이기때문에 산술연산이 적용되지 않아 제외함.
colSums(iris[,-5]) # 열별 합계
> Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
colMeans(iris[,-5]) # 열별 평균
rowSums(iris[,-5]) # 행별 합계
rowMeans(iris[,-5]) # 행별 평균
> [1] 2.550 2.375 2.350 2.350 2.550 2.850 2.425 2.525 2.225 2.400 2.700 2.500
[13] 2.325 2.125 2.800 3.000 2.750 2.575 2.875 2.675 2.675 2.675 2.350 2.650
[25] 2.575 2.450 2.600 2.600 2.550 2.425 2.425 2.675 2.725 2.825 2.425 2.400
[37] 2.625 2.500 2.225 2.550 2.525 2.100 2.275 2.675 2.800 2.375 2.675 2.350
[49] 2.675 2.475 4.075 3.900 4.100 3.275 3.850 3.575 3.975 2.900 3.850 3.300
[61] 2.875 3.650 3.300 3.775 3.350 3.900 3.650 3.400 3.600 3.275 3.925 3.550
[73] 3.800 3.700 3.725 3.850 3.950 4.100 3.725 3.200 3.200 3.150 3.400 3.850
[85] 3.600 3.875 4.000 3.575 3.500 3.325 3.425 3.775 3.400 2.900 3.450 3.525
[97] 3.525 3.675 2.925 3.475 4.525 3.875 4.525 4.150 4.375 4.825 3.400 4.575
[109] 4.200 4.850 4.200 4.075 4.350 3.800 4.025 4.300 4.200 5.100 4.875 3.675
[121] 4.525 3.825 4.800 3.925 4.450 4.550 3.900 3.950 4.225 4.400 4.550 5.025
[133] 4.250 3.925 3.925 4.775 4.425 4.200 3.900 4.375 4.450 4.350 3.875 4.550
[145] 4.550 4.300 3.925 4.175 4.325 3.950
2. 행과 열의 방향 전환
z <- matrix(1:20, nrow=4,ncol=5)
> [,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
t(z)
> [,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20t() 함수는 행과 열의 방향을 transpose(변환) 해주는 함수이다.
3. 조건 검색
# 품종 열이 setosa인 행만 추출
IR.1 <- subset(iris, Species=='setosa')
# Sepal.Length 의 값이 5.0보다 크고 Sepal.width값이 4.0보다 큰 행만 추출
IR.2 <- subset(iris, Sepal.Length>5.0 & Sepal.Width>4.0)subset() 함수는 subset(대상데이터, 조건) 의 형식으로 사용된다.
데이터프레임에서는 잘 작동되지만 매트릭스에서는 잘 작동되지 않으므로
데이터프레임으로 변환한후 사용해야한다.
4. 산술연산 적용
숫자로 구성된 매트릭스나 데이터 프레임에 대해서도 산술연산을 적용할 수 있다.
a <- matrix(1:6, 3, 2)
> [,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
b <- matrix(5:10, 3, 2)
> [,1] [,2]
[1,] 5 8
[2,] 6 9
[3,] 7 10
2*a
> [,1] [,2]
[1,] 2 8
[2,] 4 10
[3,] 6 12
a+b
> [,1] [,2]
[1,] 6 12
[2,] 8 14
[3,] 10 16매트릭스에 대한 산술연산은 안에 저장된 값들에 대한 연산으로 바뀌어 실행된다.
매트릭스 a,b를 더하는 연산은 동일한 위치에 있는 값들 간에 더하는 연산으로 바뀌어 실행된다.
매트릭스 간의 연산에서는 동일한 크기(행,열 개수) 를 가져야한다.
5. 자료구조 변환
매트릭스로, 데이터프레임으로 자료구조를 변환할 수 있다.
m <- as.matrix(iris[,1:4]) # 데이터프레임을 매트릭스로 변환
df <- as.data.frame(m) # 매트릭스를 데이터프레임으로 변환데이터 프레임을 매트릭스로 변환할 때에는 매트릭스에 저장될 모든 값들의 자료형은 동일해야한다.
데이터 프레임에만 적용되는 열 추출
위에서 서술된 함수들은 매트릭스,데이터프레임 모두 동일하게 적용이 되는 함수들이다.
하지만
매트릭스에서는 안되고 데이터프레임에서만 적용되는 방법이 있다.
- 특정 열에 저장된 데이터 추출 * 데이터프레임만 가능
# iris데이터셋 품종 데이터 추출
iris["Species"]
iris[5]기존의 2차원구조의 데이터 추출에는 인덱스 2개가 필요하다 [ 행, 열 ]
하지만 데이터 프레임에서는 하나의 인덱스만 가지고 데이터를 추출할 수 있는데
하나의 인덱스는 '열'을 의미한다.
이런 방식으로 열을 추출하면 결과가 벡터가 아닌 데이터프레임 형태로 추출된다.
# 실행결과
> iris["Species"]
Species
1 setosa
2 setosa
3 setosa
4 setosa
5 setosa
.
.
.
2. $ 사용
또한 데이터셋 이름 다음에 $열이름 을 붙여서 추출할 수도 있다.
iris$Species이도 마찬가지로 데이터 프레임에만 적용되며 결과는 벡터형식으로 추출된다.
iris[,"Species"] 와 같은 결과를 도출한다.
# 실행결과
> iris$Species
[1] setosa setosa setosa setosa setosa setosa
[7] setosa setosa setosa setosa setosa setosa
[13] setosa setosa setosa setosa setosa setosa
[19] setosa setosa setosa setosa setosa setosa
.
.
.


'Language > R' 카테고리의 다른 글
| [ R ] 막대 그래프 barplot() , par()함수 (0) | 2023.01.17 |
|---|---|
| [ R ] .csv .xlsx 파일 저장, 불러오기 (0) | 2023.01.17 |
| [ R ] 데이터 프레임 DataFrame (0) | 2023.01.17 |
| [ R ] 매트릭스 Matrix (0) | 2023.01.17 |
| [ R ] 리스트 List (0) | 2023.01.17 |


